
一、准备
1.1 拉取镜像
docker search hbase
选择 star 最高的 harisekhon/hbase
docker pull harisekhon/hbase
1.2 启动镜像
docker run -d -p 2181:2181 -p 8080:8080 -p 8085:8085 -p 9090:9090 -p 9095:9095 -p 16000:16000 -p 16010:16010 -p 16030:16030 -p 16020:16020 -p 16201:16201 -p 16301:16301 -p 50070:50070 -p 50090:50090 --name hbase001 harisekhon/hbase
这么多端口的映射是为了后续通过脚本操作Hbase。
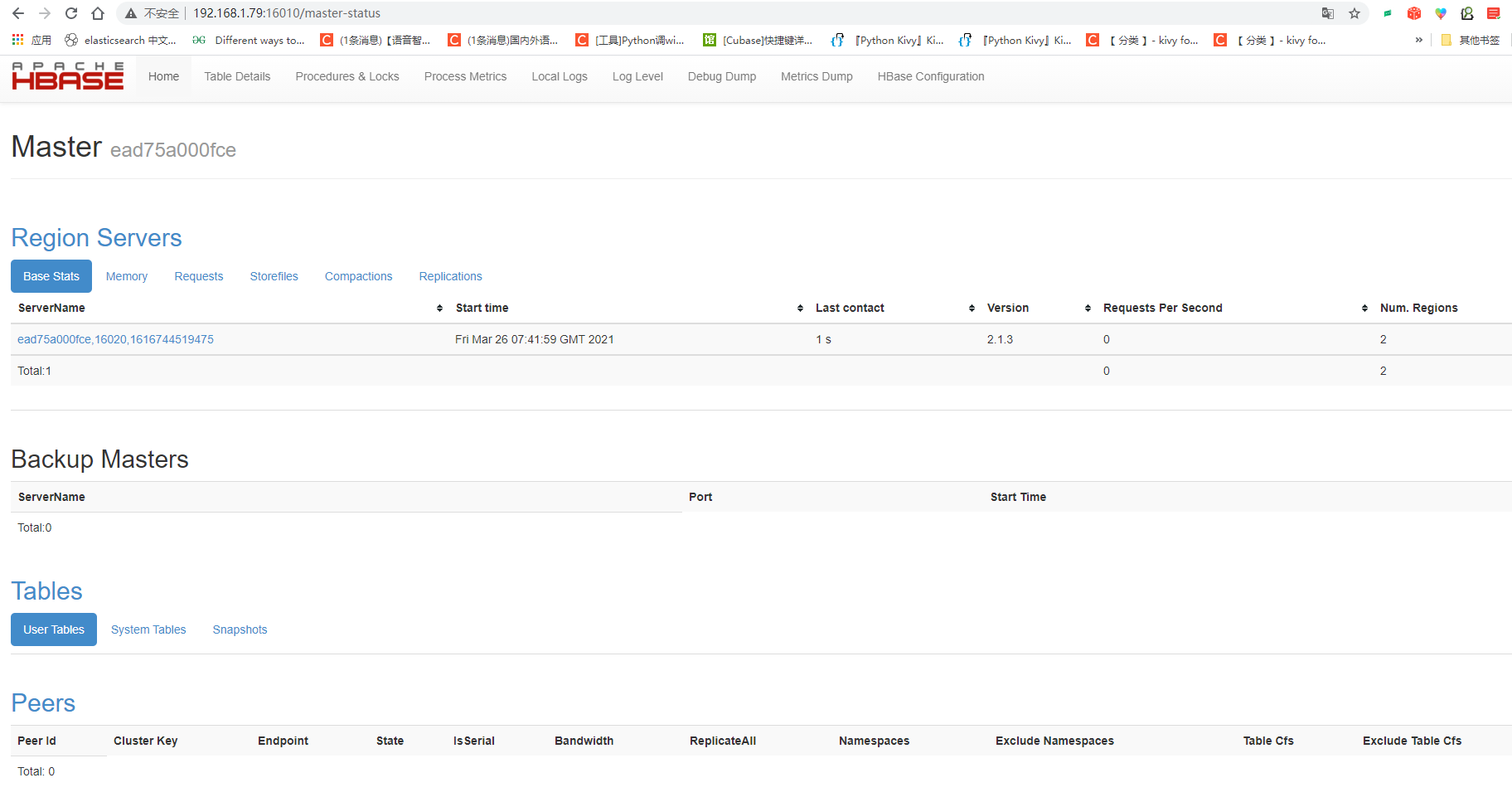
访问localhost:16010,界面如下:
若出现端口占用情况
# 查看指定端口信息
netstat -tunlp | grep 8080
# 查看占用的进程信息
ps 29142
1.3 多语言连接支持
打开并编辑 /hbase/conf/hbase-site.xml 文件,在 configuration 中追加如下内容
<property>
<name>hbase.regionserver.thrift.framed</name>
<value>true</value>
</property>
<property>
<name>hbase.regionserver.thrift.compact</name>
<value>true</value>
</property>
<property>
<name>hbase.thrift.server.socket.read.timeout</name>
<value>86400000</value>
</property>
<property>
<name>hbase.thrift.connection.max-idletime</name>
<value>31104000</value>
</property>
Python脚本连接
import happybase
host = '192.168.1.79'
port = 9090
hbase_conn = happybase.Connection(
host=host,
port=port,
protocol="compact",
transport="framed"
)
table_list = hbase_conn.tables()
print(table_list)
二、Hbase命令行操作
进入容器:
docker exec -it hbase001 bash
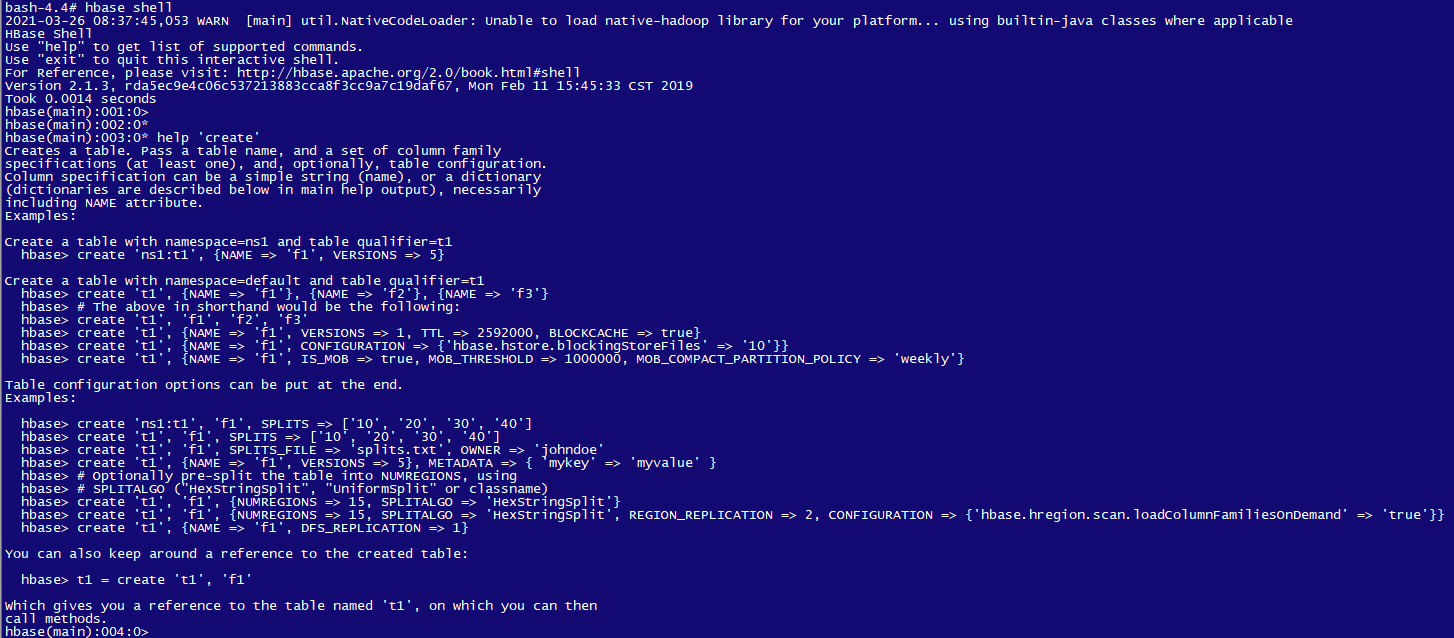
容器中执行如下命令,进入Hbase shell
hbase shell
Hbase shell 如下图:

在进行基本增删改查操作之前,我们需要先创建数据表,通过 help 'create' 命令可以查看create命令的详情。
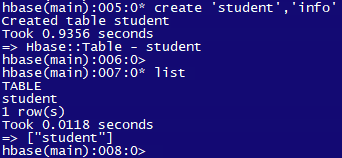
通过命令 create 'student','info' 创建一个命名空间为default,表名为student,列族为info的表。通过 list 命令可以查看所有的表:
* 命名空间类似于MySQL中的数据库
* 删除数据库:disable <表名>,drop <表名>
2.1 增
put 'student','1','info:name','xiaoming'
put 'student','1','info:age','12'
put 'student','2','info:name','zhangsan'
put 'student','2','info:age','56'
put 'student','a1','info:name','michael'
put 'student','a1','info:age','18'
put 'student','3','info:name','lily'
put 'student','3','info:age','15'
put 'student','21','info:name','xinxin'
put 'student','21','info:age','26'
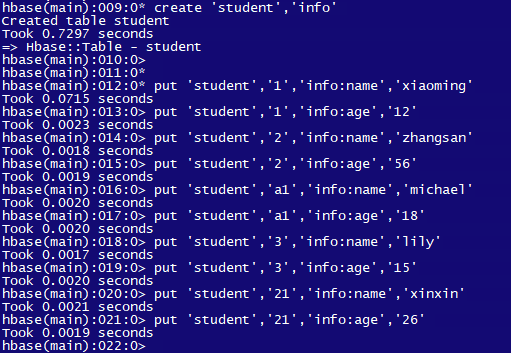
scan 'student' 可以查看表中的所有数据:
* Hbase Rowkey 使用字典序
2.2 删
deleteall 'student','a1' -- 删除该rowkey下的所有数据
delete 'student','a1','info:name' -- 删除某一cell的数据

2.3 改
改即为增
2.4 查
1. 根据 rowkey 查询
get 'student','2';
get 'student','2','info:name
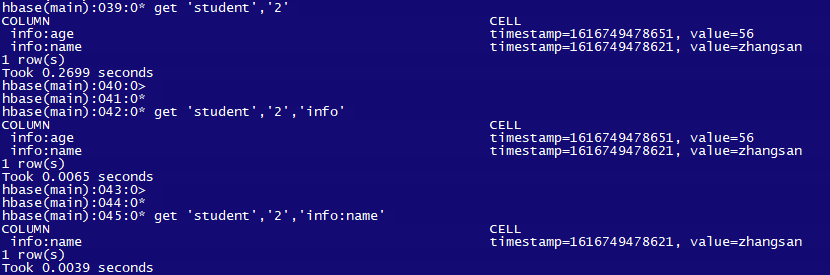
2. 扫描表 scan
# 查询全表
scan 'test'
前面我们删掉了 rowkey 等于 a1 的用户的所有数据,现在查看所有用户:

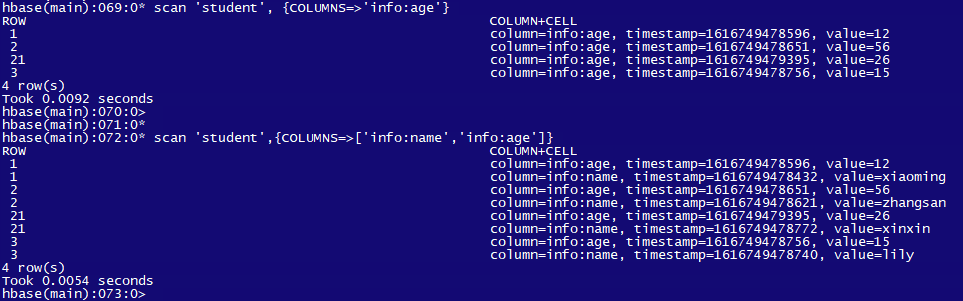
3. 查询指定字段
scan 'student', {COLUMNS=>'info:age'} -- 单个字段
scan 'student',{COLUMNS=>['info:name','info:age']} -- 多个字段
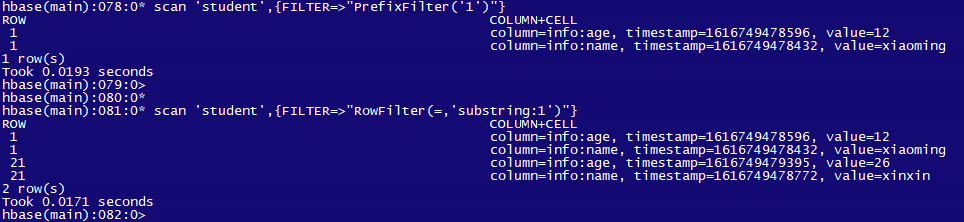
4. 过滤查询
# rowkey 以 1 开头的:
scan 'student',{FILTER=>"PrefixFilter('1')"}
# rowkey 包含 1 的:
scan 'student',{FILTER=>"RowFilter(=,'substring:1')"}
# 查找字段n开头,且值包含 x 的数据:
scan 'student',{FILTER=>"ColumnPrefixFilter('n') AND ValueFilter(=,'substring:x')"}
# 根据时间戳查询
scan 'student',{FILTER=>"TimestampsFilter(1616749478596,1616749478740,1616749478772)"}
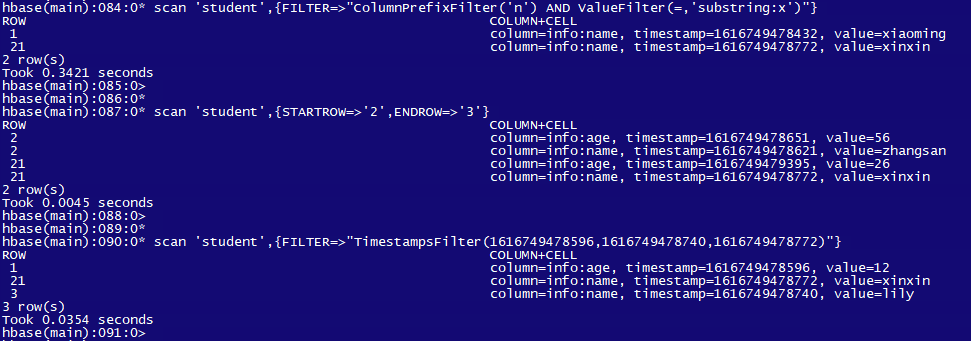
5. rowkey 属于 ['1','11']范围的
scan 'student',{STARTROW=>'2',ENDROW=>'3'}
6. 倒排序查询
scan 'student',{LIMIT=>3,REVERSED=>true}

7. 统计多少条数据
count 'student',{INTERVAL=>1000}

三、集群
请参考这里


0 评论
大哥整点话呗~