前言
- 本文将使用docker搭建hbase集群,集群是一个master(主机名hadoop0),两个salve(主机名Hadoop1,Hadoop2)。
- 开始前,请先选择创建搭建过程中所需软件的安装路径,本文:/usr/local/work ;/opt/hbase
- 搭建过程出现许多问题,虽已解决但可能安装了多余的依赖包,导致制作出来的基础镜像体积较大。
- “#”表示注释;“$”表示命令输入;“>”表示命令输出;“=>”表示文件中写入。
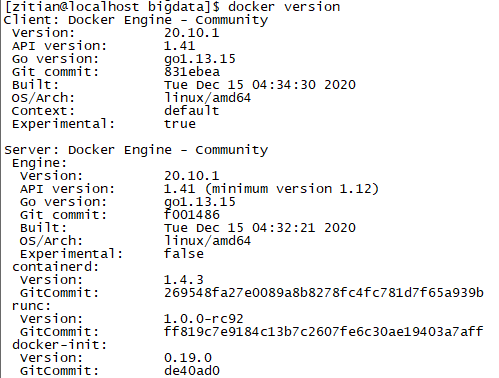
docker 版本
材料 | 软件 | 版本 | | --- | --- | | OpenSSH | | | JDK | 1.8 | | Hadoop | 2.10.1 | | Zookeeper | 3.5.9 | | Hbase | 2.2.6 | | Maven | 3.6.2 | | Thrift | 0.13.0 | | Snappy | 1.1.3 |
一、基础镜像
章节 1.2 ~ 1.9 所有操作请在容器中执行,1.1 和 1.10在容器主机执行
1.1 基于 CentOS 7.8.2003
docker pull centos:7.8.2003
docker run -itd --network=host --privileged=true --name hbase_basic afb6fca791e0 /usr/sbin/init
docker exec -it hbase_basic /bin/bash
# 容器中执行
$ yum -y install wget net-tools.x86_64
hbase_basic:自定义的容器名
afb6fca791e0:拉取的centos镜像id
1.2 安装 java1.8
# yum 安装java1.8
$ yum install java-1.8.0-openjdk* -y
# 使用命令检查是否安装成功
$ java -version
> openjdk version "1.8.0_282"
> OpenJDK Runtime Environment (build 1.8.0_282-b08)
> OpenJDK 64-Bit Server VM (build 25.282-b08, mixed mode)
# 查询java安装路径
# 可知java安装路径为:/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.el7_9.x86_64/
$ which java
> /usr/bin/java
$ ls -lrt /usr/bin/java
> lrwxrwxrwx. 1 root root 22 Mar 1 05:48 /usr/bin/java -> /etc/alternatives/java
$ ls -lrt /etc/alternatives/java
> lrwxrwxrwx. 1 root root 73 Mar 1 05:48 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.el7_9.x86_64/jre/bin/java
# 环境变量配置
$ vi /etc/profile
=> export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.el7_9.x86_64
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
1.3 安装 Thrift
介绍
https://developer.aliyun.com/article/88299
下载
官网:http://archive.apache.org/dist/thrift/0.13.0/
或:thrift-0.13.0.tar.gz
依赖
yum install -y make automake autoconf libtool flex bison pkgconfig gcc gcc-c++ boost-devel libevent-devel zlib-devel python-devel ruby-devel openssl-deve
安装
$ cd /usr/local/work
$ tar -zxvf thrift-0.13.0.tar.gz
$ cd thrift-0.13.0
$ ./configure
$ make && make install
验证
# 显示版本号即安装成功
$ thrift -version
> Thrift version 0.13.0
1.4 安装 Maven
用于源码安装 hadoop 时编译源码,如果不是源码安装也建议在系统中安装 Maven
下载
官网:https://maven.apache.org/download.cgi
或:apache-maven-3.6.2-bin.tar.gz
$ cd /usr/local/work
$ tar -xvf apache-maven-3.6.2-bin.tar.gz
配置环境变量
# 编辑全局环境变量配置文件
$ vi /etc/profile
=> export M2_HOME=/usr/local/work/apache-maven-3.6.2 # Maven安装路径
export PATH=$PATH:$M2_HOME/bin
# 使环境变量生效
$ source /etc/profile
验证
# 输出 apache maven 版本号,证明安装成功
$ mvn -version
> Apache Maven 3.6.2 (40f52333136460af0dc0d7232c0dc0bcf0d9e117; 2019-08-27T15:06:16Z)
> Maven home: /usr/local/work/apache-maven-3.6.2
> Java version: 1.8.0_282, vendor: Red Hat, Inc., runtime: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.el7_9.x86_64/jre
> Default locale: en_US, platform encoding: ANSI_X3.4-1968
> OS name: "linux", version: "4.18.0-193.el8.x86_64", arch: "amd64", family: "unix"
$ rm apache-maven-3.6.2-bin.tar.gz
1.5 安装 Snappy
下载
官方:https://src.fedoraproject.org/repo/pkgs/snappy/
或:snappy-1.1.3.tar.gz
依赖
yum install -y openssl openssl-devel openssl-libs snappy snappy-devel bzip2 bzip2-devel jansson jansson-devel fuse fuse-devel libgcc protobuf protobuf-compiler
安装
$ cd /usr/local/work
$ tar -xvf snappy-1.1.3.tar.gz
$ cd snappy-1.1.3
$ ./configure
$ make && make install
验证
$ ll /usr/local/lib | grep snappy
> -rw-r--r--. 1 root root 522288 Mar 11 08:52 libsnappy.a
> -rwxr-xr-x. 1 root root 955 Mar 11 08:52 libsnappy.la
> lrwxrwxrwx. 1 root root 18 Mar 11 08:52 libsnappy.so -> libsnappy.so.1.3.0
> lrwxrwxrwx. 1 root root 18 Mar 11 08:52 libsnappy.so.1 -> libsnappy.so.1.3.0
> -rwxr-xr-x. 1 root root 258640 Mar 11 08:52 libsnappy.so.1.3.0
出现如上5个文件,证明安装成功。
1.6 安装 SSH
安装
$ yum install -y openssl openssh-server openssh-clients
$ systemctl start sshd.service
$ systemctl status sshd.service
$ systemctl enable sshd.service
配置文件
$ vi /etc/ssh/sshd_config
# 找到修改(去掉注释)如下配置
=> port=22 #开启22端口
=> RSAAuthentication yes #启用 RSA 认证,centos7.4以上已弃用
=> PubkeyAuthentication yes #启用公钥私钥配对认证方式
=> AuthorizedKeysFile .ssh/authorized_keys #公钥文件路径(和上面生成的文件同)
=> PermitRootLogin yes #root能使用ssh登录
$ systemctl restart sshd.service
1.7 安装 Zookeepr
下载
官网:https://zookeeper.apache.org/releases.html
或:apache-zookeeper-3.5.9-bin.tar.gz
然后解压到/usr/local/work,并在同级目录下创建zkdata文件夹。
1.8 安装 Hadoop
下载
官网:https://hadoop.apache.org/releases.html
然后解压到 /opt/hbase(请自行创建该文件夹)
配置
打开解压后的hadoop-2.10.1文件夹,修改以下配置文件
1. java环境信息就配置
$ vi /opt/hbase/hadoop-2.10.1/etc/hadoop/hadoop-env.sh
# java安装路径查看,参考本文1.2章节
=> export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.el7_9.x86_64
2. yarn配置java环境信息
$ vi /opt/hbase/hadoop-2.10.1/etc/hadoop/yarn-env.sh
=> export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.el7_9.x86_64
3. core-site.xml
$ vi /opt/hbase/hadoop-2.10.1/etc/hadoop/core-site.xml
=> <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hbase/hadoop-2.10.1/temp</value>
</property>
</configuration>
hadoop0为集群搭建中,主节点的主机名,下同
4. hdfs-site.xml
$ vi /opt/hbase/hadoop-2.10.1/etc/hadoop/hdfs-site.xml
=> <configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hbase/hadoop-2.10.1/dfs/name</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/opt/hbase/hadoop-2.10.1/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop0:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
5. mapred-site.xml
$ vi /opt/hbase/hadoop-2.10.1/etc/hadoop/mapred-site.xml
=> <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop0:19888</value>
</property>
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
</configuration>
6. yarn-site.xml
$ vi /opt/hbase/hadoop-2.10.1/etc/hadoop/yarn-site.xml
=> <configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop0:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop0:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop0:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop0:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop0:8088</value>
</property>
</configuration>
7. slaves
hadoop1
hadoop2
文件中写入集群搭建中slave节点的主机名,文件中不能有空行,文字末尾不能有空格。
8. 配置hadoop相关环境变量
$ vi /etc/profile
=> export HADOOP_HOME=/opt/hbase/hadoop-2.10.1
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
$ source /etc/profile
执行source /etc/profile使环境变量生效;
1.9 安装 Hbase
下载
官网: https://hbase.apache.org/downloads.html
然后解压到 /opt
配置
打开解压后的hbase-2.2.6文件夹,修改以下配置文件
1. hbase-site.xml
$ vi /opt/hbase-2.2.6/conf/hbase-site.xml
=> </configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop0:9000/hbase</value>
<description>The directory shared by region servers.</description>
</property>
<property>
<name>hbase.hregion.max.filesize</name>
<value>10737418240</value>
<description>
Maximum HStoreFile size. If any one of a column families' HStoreFiles has
grown to exceed this value, the hosting HRegion is split in two.
Default: 256M.
</description>
</property>
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
<description>
Memstore will be flushed to disk if size of the memstore
exceeds this number of bytes. Value is checked by a thread that runs
every hbase.server.thread.wakefrequency.
</description>
</property>
<property>
<name>hbase.client.write.buffer</name>
<value>5242880</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>
The mode the cluster will be in. Possible values are
false: standalone and pseudo-distributed setups with managed Zookeeper
true: fully-distributed with unmanaged Zookeeper Quorum (see hbase-env.sh)
</description>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
<description>
Property from ZooKeeper's config zoo.cfg.
The port at which the clients will connect.
</description>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<property>
<name>hbase.zookeeper.property.tickTime</name>
<value>6000</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/work/zkdata</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop0:2181,hadoop1:2181,hadoop2:2181</value>
<description>
Comma separated list of servers in the ZooKeeper Quorum.
For example, "host1.mydomain.com,host2.mydomain.com,host3.mydomain.com".
By default this is set to localhost for local and pseudo-distributed modes of operation. For a fully-distributed setup, this should be set to a full list of ZooKeeper quorum servers.
If HBASE_MANAGES_ZK is set in hbase-env.sh this is the list of servers which we will start/stop ZooKeeper on.
</description>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase/master</value>
</property>
<property>
<name>hbase.regionserver.thrift.framed</name>
<value>true</value>
</property>
<property>
<name>hbase.regionserver.thrift.compact</name>
<value>true</value>
</property>
<property>
<name>hbase.thrift.server.socket.read.timeout</name>
<value>86400000</value>
</property>
<property>
<name>hbase.thrift.connection.max-idletime</name>
<value>31104000</value>
</property>
</configuration>
2. regionservers
hadoop0
hadoop1
hadoop2
文件中写入集群搭建中 regionservers 节点的主机名,文件中不能有空行,文字末尾不能有空格。
3. hbase-env.sh
$ vi /opt/hbase-2.2.6/conf/hbase-env.sh
# java安装路径查看,参考本文1.2章节
=> export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.282.b08-1.el7_9.x86_64
4. 配置文件
$ vi /etc/profile
=> export HBASE_HOME=/opt/hbase-2.2.6
export PATH=$PATH:$HBASE_HOME/bin
$ source /etc/profile
1.10 生成镜像
将配置好的容器打包成镜像,作为hbase集群搭建的基础,打包命令如下
语法
docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
OPTIONS说明:
- -a :提交的镜像作者;
- -c :使用Dockerfile指令来创建镜像;
- -m :提交时的说明文字;
- -p :在commit时,将容器暂停。
实例
将容器a404c6c174a2保存为新的镜像,并添加提交人信息和说明信息。
$ docker commit -a "artaime" -m "my hbase study" a404c6c174a2 hbase_basic:v0.1
sha256:b0bde75e3f051544e8886be23010b66577647a40bc02c0885a6600b33ee28057
$ docker images hbase_basic:v0.1
REPOSITORY TAG IMAGE ID CREATED SIZE
hbase_basic v0.1 b0bde75e3f05 15 seconds ago 629 MB
二、集群搭建
2.1 节点
使用前面制作的镜像生成三个容器:主节点:hadoop0、从节点:hadoop1、hadoop2
$ docker run --privileged=true --name hadoop0 \
--hostname hadoop0 \
-p 50070:50070 \
-p 8088:8088 \
-p 19010:22 \
-p 19090:9090 \
-p 16010:16010 \
-d b0bde75e3f05
$ docker run --privileged=true --name hadoop1 \
--hostname hadoop1 \
-p 19011:22 \
-d b0bde75e3f05
$ docker run --privileged=true --name hadoop2 \
--hostname hadoop2 \
-p 19012:22 \
-d b0bde75e3f05
b0bde75e3f05:章节1.10制作的镜像的id
完成后进入容器中执行接下来的操作
2.2 ssh登录
查看主机ip
$ ifconfig
> eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.6 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:ac:11:00:06 txqueuelen 0 (Ethernet)
RX packets 15182435 bytes 156889414913 (146.1 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 11718358 bytes 313244921520 (291.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
分别在三个容器中执行命令,可知,三个容器的ip分别为:
| 容器 | ip |
| hadoop0 | 172.17.0.6 |
| hadoop1 | 172.17.0.7 |
| hadoop2 | 172.17.0.8 |
分别修改三个容器的/etc/hosts文件,都添加如下的相同内容,注意用 Tab 键隔开:
172.17.0.6 hadoop0
172.17.0.7 hadoop1
172.17.0.8 hadoop2
分别修改三个容器的root密码
# passwd命令,修改当前用户的登录密码
$ passwd
Changing password for user root.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
$
分别在三个容器上执行命令 ssh-keygen -t rsa,一路回车下去,最终会在/root/.ssh目录下生成rsa文件。
$ ssh-keygen -t rsa
> Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:8zYPPnM7+hW56nQyG+aejYxqWMie1Ld4xxZcYEjY664 root@localhost.localdomain
The key's randomart image is:
+---[RSA 2048]----+
| +.. |
| . o o |
| o . |
| . .. |
| . oS. . .o |
| + ooo o o |
| o + +=o*.+ |
| + oo*X*% |
| .E++@&o. |
+----[SHA256]-----+
在容器hadoop0上执行如下三行命令,执行完毕后,三个容器的rsa公钥都存在/root/.ssh/authorized_keys文件中。
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ ssh root@hadoop1 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ ssh root@hadoop2 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
分别在hadoop1、hadoop2上执行以下命令,将hadoop0的authorized_keys文件复制过来。
$ ssh root@hadoop0 cat ~/.ssh/authorized_keys >> ~/.ssh/authorized_keys
由于hadoop0的authorized_keys中包含了hadoop1、hadoop2的rsa公钥,所以在hadoop1、hadoop2上以上命令是不需要登录的。
现在三个容器的公钥都已经放在每一个容器上了,它们相互之间可以免密码登录了。
2.3 Zookeeper
分别在三个容器中的zookeeper安装目录下创建 zoo.cfg文件,并修改。内容如下:
$ vi /usr/local/work/zookeeper-3.5.9/conf/zoo.cfg
=> the number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/work/zkdata
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=hadoop0:2887:3887
server.2=hadoop1:2888:3888
server.3=hadoop2:2889:3889
分别在三个容器的 /usr/local/work/zkdata 目录下创建 myid 文件,文件分别是“1”、“2”、“3”,注意不要有空行空格或其它字符
在三个容器上执行启动zookeeper命令:
$ /usr/local/work/zookeeper-3.5.9/bin/zkServer.sh start
查看集群状态:
$ /usr/local/work/zookeeper-3.5.9/bin/zkServer.sh status
2.4 Hadoop
对比章节1.8,检查三个容器中hadoop相关配置文件(/opt/hbase/hadoop-2.10.1/etc/hadoop/),注意相关配置是否与容器名一致。
检查无误,执行启动命令。
在主节点 hadoop0 上执行如下命令格式化hdfs。
$ /opt/hbase/hadoop-2.10.1/bin/hdfs namenode -format
在主节点 hadoop0 上执行如下命令启动 hadoop。
$ /opt/hbase/hadoop-2.10.1/sbin/start-all.sh
> This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [hadoop0]
hadoop0: starting namenode, logging to /opt/hbase/hadoop-2.10.1/logs/hadoop-root-namenode-hadoop0.out
hadoop2: starting datanode, logging to /opt/hbase/hadoop-2.10.1/logs/hadoop-root-datanode-hadoop2.out
hadoop1: starting datanode, logging to /opt/hbase/hadoop-2.10.1/logs/hadoop-root-datanode-hadoop1.out
Starting secondary namenodes [hadoop0]
hadoop0: starting secondarynamenode, logging to /opt/hbase/hadoop-2.10.1/logs/hadoop-root-secondarynamenode-hadoop0.out
starting yarn daemons
starting resourcemanager, logging to /opt/hbase/hadoop-2.10.1/logs/yarn-root-resourcemanager-hadoop0.out
hadoop2: starting nodemanager, logging to /opt/hbase/hadoop-2.10.1/logs/yarn-root-nodemanager-hadoop2.out
hadoop1: starting nodemanager, logging to /opt/hbase/hadoop-2.10.1/logs/yarn-root-nodemanager-hadoop1.out
$
在主节点输入 jps 看当前所有 java 进程,如下进程齐全,则表示 hadoop 的 master 启动成功。
$ jps
> QuorumPeerMain
NameNode
ResourceManager
Jps
SecondaryNameNode
在hadoop1、hadoop2上分别输入 jps 查看当前所有 java 进程,如下进程齐全,则表示 hadoop 的 slave 启动成功。
$ jps
> QuorumPeerMain
NodeManager
jps
DataNode
2.5 Hbase
三个容器中执行如下命令:
$ ln -s /opt/hbase/hadoop-2.10.1/etc/hadoop/core-site.xml /opt/hbase-2.2.6/conf/core-site.xml
$ ln -s /opt/hbase/hadoop-2.10.1/etc/hadoop/hdfs-site.xml /opt/hbase-2.2.6/conf/hdfs-site.xml
对比章节1.9,检查三个容器中 hbase 相关配置文件(/opt/hbase-2.2.6/conf/),注意相关配置是否与容器名一致。
检查无误,执行启动命令。
- 在主节点 hadoop0 上执行
start-hbase.sh命令(由于hbase/bin/已经添加到环境变量,所有此命令可以在任何目录下执行,若提示命令未找到,执行source /etc/profile) - 在 hadoop0 上执行
jps命令查看 java 进程,可以看到新增的 HMaster、和HRegionServer进程。
$ jps
> QuorumPeerMain
NameNode
HMaster
ResourceManager
HRegionServer
Jps
SecondaryNameNode
在hadoop1、hadoop2上执行 jps 命令查看 java 进程,可以看到新增的 HRegionServer 进程。
$ jps
> QuorumPeerMain
HRegionServer
NodeManager
jps
DataNode
验证hbase,执行以下命令,可以进入 hbase 的命令行模式。
$ hbase shell
> SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hbase/hadoop-2.10.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hbase-2.2.6/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.6, r88c9a386176e2c2b5fd9915d0e9d3ce17d0e456e, Tue Sep 15 17:36:14 CST 2020
Took 0.0020 seconds
hbase(main):001:0> list
TABLE
0 row(s)
Took 0.3889 seconds
=> []
hbase(main):002:0> create "store","goods"
Created table store
Took 0.8274 seconds
=> Hbase::Table - store
hbase(main):003:0>
在hadoop1或hadoop2上执行 hbase shell 命令进入命令行模式,再次执行 list 命令查看表信息,若看到刚刚在hadoop0上创建的 store 表,则表示 hbase 启动成功。
三、使用
3.1 配置 snappy 压缩算法
3.2 多语言接口支持
由于容器中已经安装了thrift,所以只需运行如下的命令
/opt/hbase-2.2.6/bin/bin/hbase-daemons.sh start thrift
四、问题


0 评论
大哥整点话呗~